수표 손글씨 숫자 인식 문제를 위한 심층 함성곱 신경망
입력: [batchsize x 28 x 28 x1] 28x28 Greyscale
합성곱_1: [batchsize x 28 x 28 x 32] 5x5커널을 가진 합성곱층1/strides=1(same padding)
폴링_1: [batchsize x 14 x 14 x 32] 2x2 최대 풀링 연산1/strides=2
합성곱_2: [batchsize x 28 x 28 x 64] 5x5커널을 가진 합성곱층2/strides=1(same padding)
폴링_2: [batchsize x 7 x 7 x 64] 2x2 최대 폴링 연산2/strides=2
완전 연결_1: [batchsize x 1024]
완전 연결과 소프트맥스 층: [batchsize x 10]
Prepare data(MNIST)
import tensorflow_datasets as tfds
import tensorflow as tf
mnist_bldr=tfds.builder('mnist')
mnist_bldr.download_and_prepare()
datasets=mnist_bldr.as_dataset(shuffle_files=False)
mnist_train_orig=datasets['train']
mnist_test_orig=datasets['test']
BUFFER_SIZE=10000
BATCH_SIZE=64
NUM_EPOCHS=20
mnist_train=mnist_train_orig.map(
lambda item:(tf.cast(item['image'], tf.float32)/255.0, tf.cast(item['label'], tf.int32)))
mnist_test=mnist_test_orig.map(
lambda item:(tf.cast(item['image'], tf.float32)/255.0, tf.cast(item['label'], tf.int32)))
tf.random.set_seed(1)
mnist_train=mnist_train.shuffle(buffer_size=BUFFER_SIZE, reshuffle_each_iteration=False)
mnist_valid=mnist_train.take(10000).batch(BATCH_SIZE)
mnist_train=mnist_train.skip(10000).batch(BATCH_SIZE)
CNN implements with Tensorflow Keras API(Sequential)
tf.keras.layers.Conv2Dtf.kears.layers.MaxPooling2D
tf.keras.layers.AvgPooling2D
tf.keras.layers.Dropout
Conv2D 클래스로 층을 구성하려면 필터개수(출력 특성 맵의 개수)와 커널 크기를 지정해야 한다.
그 외에서 스라이드(기본값은 x, y차원으로 1)와 패딩(세임 패딩과 밸리드 패딩)을 지정할 수 있다.
일반적으로 이미지를 읽을 때 채널의 차원은 텐서 배열의 마지막 차원이다.
(NHWC 포맷, N: 배치에 있는 이미지 개수, H: Height, W: Weight, C: Channel)
일반적으로 Conv2D 클래스는 기본적으로 입력이 NHWC 포맷일 것이라고 가정한다.
만일 데이터의 포맷을 바꾸어야 한다면, data_format=“channels_first”로 변경할 수 있다.(NCHW)
MaxPool2D와 AvgPool2D는 각각 최대 풀링과 평균 풀리을 구현한다.
pool_size 매개변수는 최대나 평균을 계산하기 위한 윈도(또는 이웃)의 크기를 결정한다.
stides 매개변수를 사용하여 폴링 층의 동작을 제어할 수 있다.
Dropout 클래스는 규제를 위한 드롭아웃 층을 구현한다.
rate 매개변수를 통해 훈련하는 동안 입력 유닛을 드롭아웃할 확률을 결정한다.
training 매개변수로 훈련을 위해 호출하는 것인지 추론을 위해 호출하는 것인지 지정하여
드롭 아웃층의 동작을 제어할 수 있다.(추론을 할 때는 드롭아웃을 하지 않음)
model=tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=(5, 5), strides=(1, 1), padding='same', data_format='channels_last', name='conv_1', activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2), name='pool_1'))
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(5, 5), strides=(1, 1), padding='same', name='conv_2', activation='relu'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2), name='pool_2'))
모델의 특성 맵의 크기
model.compute_output_shape(input_shape=(16, 28, 28, 1))
TensorShape([16, 7, 7, 64])
밀집(완전 연결) 층
model.add(tf.keras.layers.Flatten())
model.compute_output_shape(input_shape=(16, 28, 28, 1))
드롭아웃 층
model.add(tf.keras.layers.Dense(units=1024, name='fc_1', activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.5))
model.add(tf.keras.layers.Dense(units=10, name='fc_2', activation='softmax'))
MNIST 데이터셋의 클레스 레이블 열 개에 댕으하는 열개의 출력 유닛을 가진 마지막 층(fc_2) 정의
softmax 활성화 함수로 지정함으로서 입력 샘플의 클래스 소속 확률을 알 수 있다.
model build and compile
tf.random.set_seed(1)
model.build(input_shape=(None, 28, 28, 1))
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_1 (Conv2D) (None, 28, 28, 32) 832
_________________________________________________________________
pool_1 (MaxPooling2D) (None, 14, 14, 32) 0
_________________________________________________________________
conv_2 (Conv2D) (None, 14, 14, 64) 51264
_________________________________________________________________
pool_2 (MaxPooling2D) (None, 7, 7, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 3136) 0
_________________________________________________________________
fc_1 (Dense) (None, 1024) 3212288
_________________________________________________________________
dropout (Dropout) (None, 1024) 0
_________________________________________________________________
fc_2 (Dense) (None, 10) 10250
=================================================================
Total params: 3,274,634
Trainable params: 3,274,634
Non-trainable params: 0
_________________________________________________________________
모델의 레이블이 희소한 레이블을 사용하는 다중 분류이기 때문에 SparseCategorcalCrossentropy 사용
Adam 옵티마이저tf.keras.optimizers.Adam()
Adam 옵티마이저는 안정적인 그레이디언트 기반의 최적화 방법으로 비볼록 최적화(nonconvex optimization)와
머신 러닝 문제에 잘 맞다.
Adam은 그레이디언트 모먼트(moment)와 이동 평균(running average)를 바탕으로 업데이트 단계 크기를 선택한다.
Adam 옵티마이저는 전체 기간 중 최근 데이터에 큰 비중을 두어 계산한다.(지수 이동 평균)
fit
history=model.fit(mnist_train, epochs=NUM_EPOCHS, validation_data=mnist_valid, shuffle=True)
782/782 [==============================] - 14s 8ms/step - loss: 0.1375 - accuracy: 0.9573 - val_loss: 0.0497 - val_accuracy: 0.9838
Epoch 2/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0450 - accuracy: 0.9860 - val_loss: 0.0400 - val_accuracy: 0.9878
Epoch 3/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0295 - accuracy: 0.9907 - val_loss: 0.0424 - val_accuracy: 0.9880
Epoch 4/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0231 - accuracy: 0.9927 - val_loss: 0.0409 - val_accuracy: 0.9891
Epoch 5/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0187 - accuracy: 0.9943 - val_loss: 0.0385 - val_accuracy: 0.9897
Epoch 6/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0147 - accuracy: 0.9952 - val_loss: 0.0475 - val_accuracy: 0.9891
Epoch 7/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0133 - accuracy: 0.9960 - val_loss: 0.0343 - val_accuracy: 0.9922
Epoch 8/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0116 - accuracy: 0.9963 - val_loss: 0.0373 - val_accuracy: 0.9906
Epoch 9/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0123 - accuracy: 0.9961 - val_loss: 0.0362 - val_accuracy: 0.9906
Epoch 10/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0090 - accuracy: 0.9970 - val_loss: 0.0415 - val_accuracy: 0.9915
Epoch 11/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0096 - accuracy: 0.9966 - val_loss: 0.0468 - val_accuracy: 0.9903
Epoch 12/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0062 - accuracy: 0.9980 - val_loss: 0.0471 - val_accuracy: 0.9911
Epoch 13/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0075 - accuracy: 0.9976 - val_loss: 0.0663 - val_accuracy: 0.9889
Epoch 14/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0074 - accuracy: 0.9977 - val_loss: 0.0602 - val_accuracy: 0.9894
Epoch 15/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0063 - accuracy: 0.9978 - val_loss: 0.0560 - val_accuracy: 0.9907
Epoch 16/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0047 - accuracy: 0.9985 - val_loss: 0.0635 - val_accuracy: 0.9898
Epoch 17/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0094 - accuracy: 0.9973 - val_loss: 0.0468 - val_accuracy: 0.9914
Epoch 18/20
782/782 [==============================] - 5s 7ms/step - loss: 0.0053 - accuracy: 0.9983 - val_loss: 0.0669 - val_accuracy: 0.9902
Epoch 19/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0055 - accuracy: 0.9984 - val_loss: 0.0603 - val_accuracy: 0.9906
Epoch 20/20
782/782 [==============================] - 6s 7ms/step - loss: 0.0064 - accuracy: 0.9982 - val_loss: 0.0690 - val_accuracy: 0.9887
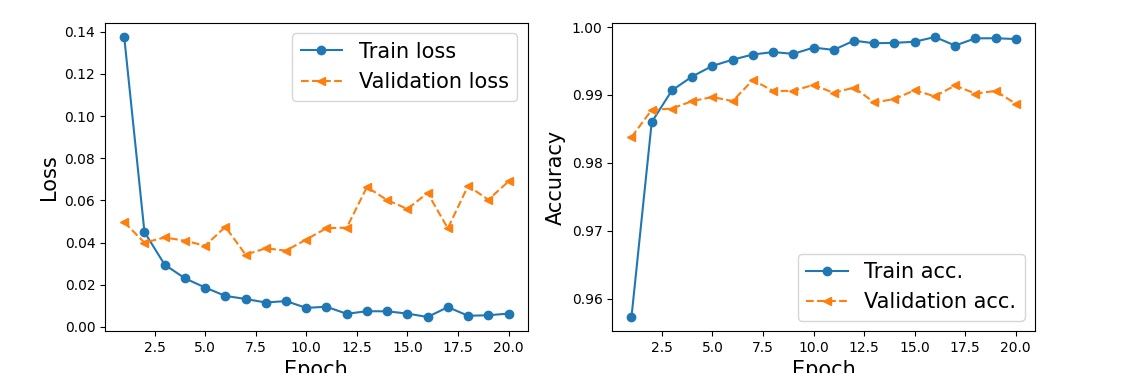
Bonita에서 Validation Acc와 Loss, val_loss가 어처구니 없이 나왔음…Giovanni에서 재테스트 예정
GPU를 탑재하고 있는 Giovanni는 확습 속도가 월등히 빨랐으며,
출력결과 또한 이상없이 출력 되었다.(위의 fit 계산 결과는 GIovanni에서 계산한 결과이다.)
맥버전 텐서플로우 validation관련 오류가 있는 걸로 보임
학습곡선
import matplotlib.pyplot as plt
import numpy as np
hist=history.history
x_arr=np.arange(len(hist['loss']))+1
fig=plt.figure(figsize=(12, 4))
ax=fig.add_subplot(1, 2, 1)
ax.plot(x_arr, hist['loss'], '-o', label='Train loss')
ax.plot(x_arr, hist['val_loss'], '--<', label='Validation loss')
ax.set_xlabel('Epoch', size=15)
ax.set_ylabel('Loss', size=15)
ax.legend(fontsize=15)
ax=fig.add_subplot(1, 2, 2)
ax.plot(x_arr, hist['accuracy'], '-o', label='Train acc.')
ax.plot(x_arr, hist['val_accuracy'], '--<', label='Validation acc.')
ax.legend(fontsize=15)
ax.set_xlabel('Epoch', size=15)
ax.set_ylabel('Accuracy', size=15)
plt.show()
test_results=model.evaluate(mnist_test.batch(20))
print('테스트 정확도: {:.2f}%'.format(test_results[1]*100))
테스트 정확도: 99.22%
이전에 DNNClassifier 추정기를 사용했을 때 90%의 정확도를 얻었지만, CNN 모델은 99.22%의 정확도를 달성했다.
클래스 소속 확률 형태로 예측 결과를 얻은 후, tf.argmax 함수로 확률이 최대인 원소를 찾아 예측 레이블로 바꾸기
batch_test=next(iter(mnist_test.batch(12)))
preds=model(batch_test[0])
tf.print(preds.shape)
TensorShape([12, 10])
preds=tf.argmax(preds, axis=1)
print(preds)
tf.Tensor([2 0 4 8 7 6 0 6 3 1 8 0], shape=(12,), dtype=int64)
fig=plt.figure(figsize=(12, 4))
for i in range(12):
ax=fig.add_subplot(2, 6, i+1)
ax.set_xticks([]); ax.set_yticks([])
img=batch_test[0][i, :, :, 0]
ax.imshow(img, cmap='gray_r')
ax.text(0.9, 0.1, '{}'.format(preds[i]), size=15, color='blue', horizontalalignment='center', verticalalignment='center', transform=ax.transAxes)
plt.show()
데이터셋 저장
import os
if not os.path.exits('models'):
os.mkdir('models')
model.save('models/mnist-cnn.h5')